ta v2.0.0: three libraries on one audited spec
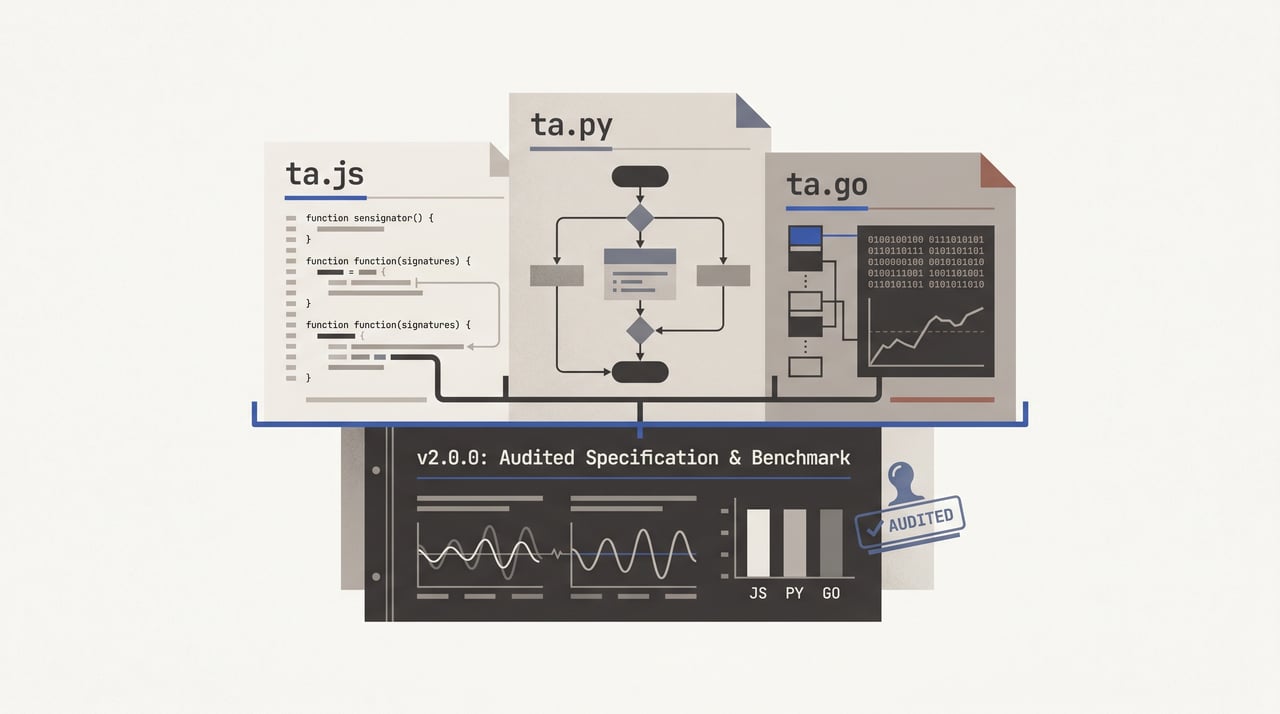
Two weeks ago, ta v2.0.0 shipped — across all three sibling libraries at once. ta.js, ta.py, and ta.go all moved to the same major version on the same release cut, with the same hundred-something indicator functions audited end-to-end against textbook formulas and a comparative benchmark in each language against the libraries each one is actually competing with. The reason it is a single version bump rather than three separate version bumps is that the libraries had drifted apart enough over the last few years that fixing each one independently would have meant fixing the same indicator three times and doing the alignment work afterwards anyway. So I did the alignment work first.
The correctness and speed of a technical-analysis library should travel between languages, not be a JS-only story. Same audited indicators, same comparative benchmark methodology, same zero-dependency posture. ta.js, ta.py, and ta.go now agree on what an RSI is supposed to return, and each one has been measured against the libraries it would actually be benchmarked against in its own ecosystem.
I wrote about the v1.17.0 modernisation pass on ta.js separately a little while ago — the source-layout cleanup, the esbuild bundle pipeline, the registry indirection that preserves the override pattern. v2.0.0 is the next chapter of the same library, and the chapter where the cross-language siblings finally catch up to it on a common spec.
The shape
Three repositories, one library family. ta.js for JavaScript, ta.py for Python, ta.go for Go. The repos sit at github.com/Bitvested/ta.js, github.com/Bitvested/ta.py, and github.com/Bitvested/ta.go. Across all three, the indicator surface is the same: moving averages, oscillators, bands, volatility indicators, statistics, chart transforms, around a hundred functions per library, each kept short enough to read in one sitting.
What v2.0.0 actually contributes, in plain terms:
-
An indicator-by-indicator audit against the standard textbook formulas, with formula bugs caught and fixed across all three implementations.
-
A comparative benchmark per library, comparing each implementation against the libraries that compete with it in the same language ecosystem.
-
A bench harness that ships in each repo and is meant to be re-run by anyone who cares to verify the numbers — hardware specified, competitor versions pinned.
-
The same zero-runtime-dependency posture the libraries had before v2.0.0, preserved as a hard family-wide constraint. None of these libraries pull in a third-party at runtime, in any language.
The audit was the unglamorous half

The starting point of v2.0.0 was that I had to admit the v1 test suites — across all three libraries, but most embarrassingly in ta.js — were not actually telling me whether the indicators were correct. The fixtures had been generated from the implementations themselves at the time those implementations were written. If the implementation was wrong then, the fixture is wrong now, and the test was asserting nothing more than “the wrong output is stably wrong.” I started ta.js in 2020 when I needed indicator functions for my own work and writing each of them was the cleanest way to learn them. Some of the indicators I wrote in those first three weeks are among the ones the audit caught.
Six indicators in ta.js came back with formula bugs that had been fossilised in the fixtures: parabolic SAR, k-means clustering, the Wilder smoothed moving average, ichimoku, momentum oscillator, and fractals in price-mode. The smoothed moving average was the cleanest example of the pattern. The v1 formula was dimensionally wrong, the fixture was captured from the wrong formula, and a green test suite had been certifying the wrong answer for years. The corrected implementation is short enough to read at a glance:
function smma(data, length=14) {
const n = data.length;
if (n < length) return [];
let seed = 0;
for (let i = 0; i < length; i++) seed += data[i];
let prev = seed / length;
const out = [prev];
for (let i = length; i < n; i++) {
prev = prev + (data[i] - prev) / length;
out.push(prev);
}
return out;
}
A length-N SMA seed, then a Wilder rolling update of prev + (data[i] - prev) / length for the rest of the series. The same fix landed in ta.py and ta.go, because the same broken formula was in all three. Reading the audit notes against the fixtures is what made me realise the suite itself was the problem, not the indicators it was failing to flag.
I felt a bit embarrassed about it but I do not really mind it that much. These six are some of the first ta.js indicators I ever wrote, and I have grown since. I am happy to have caught all of them now. Going into the audit I knew there would be issues that had never been caught — it is the kind of thing you only see by reading every function against a textbook, and that is not the kind of pass you do casually. It is the kind of pass you do once you have decided to break the version cleanly.
The cross-language reach of the audit was the part I had not anticipated. ta.py’s rsi, for example, had been computing Cutler RSI — a strict sliding window of the last length-1 deltas — where the textbook (and the corrected ta.js) uses Wilder smoothing seeded from the mean of the first length gains and losses. Same indicator name, two different algorithms, both green against fixtures captured from themselves. The fix landed in ta.py with a MIGRATION.md entry, and ta.py’s wrsi is now a thin alias for rsi so the legacy callers still resolve.
The audit moved as fast as it did because I had agentic coding tools doing the proof-reading and the cross-referencing that I would otherwise have done one indicator at a time, by hand, against the textbook. Three libraries’ worth of formula auditing, line by line, would have eaten weeks without that help. With it the work fit into a single release-shaped window where I could keep all three implementations in my head at the same time, and that is the only reason the multi-language scope was tractable on a solo timeline.
The bench was the surprising half
Once the audit was done and every indicator was producing what the textbook says it should, the obvious next question was how the library was actually performing against its competitors. As far as I have been able to find, there is no widely accepted comparative benchmark for technical-analysis libraries in any of these three languages with enough rigour around hardware specification and competitor versions to be reproducible. I wanted the library to be measurable on something other than its own internals.
For ta.js the comparison set was the obvious one: technicalindicators 3.1.0, trading-signals 7.4.3, @debut/indicators 1.3.22, and tulind 0.8.20. The first three are pure-JavaScript libraries; tulind is a Node binding to a C library. I included tulind deliberately. The practical question a developer is asking when they pick a library is “should I install the native bindings for the speed?” and the only way to answer that question honestly is to actually run the comparison.
The result was that pure-JS ta.js won 66 of 67 cross-library cases at 100,000 bars on an Apple M3 running Node v25.1.0, including against tulind. The remaining one — Rate of Change — is around 22% behind @debut/indicators at 100k, which is a constant-factor gap I have not closed yet and will pick up in a later round. The rest of the field is comfortably behind. I had been kind of expecting the C bindings to lose at the sizes a real workload runs at — the FFI marshaling cost is paid once per call regardless of how much math the call does, so as the work per call gets bigger the C tax compounds against itself — but I had not expected the win to be quite as comprehensive across the rest of the field. The numbers are quotable on the same hardware. Ratios travel between machines, absolute ops/sec do not. The full table is at BENCHMARKS.md and the reproduction steps are in bench/README.md.
The Python bench is where v2.0.0 found out it was telling itself a cleaner story than the work supported. I built the ta.py benchmark expecting the library to be competitive against the C-bound Python options the way ta.js was against tulind. It was not. The C-bound Python libraries were roughly a hundred times faster than pure-Python ta.py. That was a setback, and I wrote it down as one in my own notes before I had figured out what to do about it.
What I figured out, in hindsight, is that the comparison was not actually fair. ta.py is a pure-Python library by design, and the zero-runtime-dependency posture is a family-wide constraint, not a per-language preference. Adding C bindings would not have made ta.py faster on its own terms; it would have made it a wrapper around someone else’s C library, which is not the library it sets out to be.
The competitors actually pinned in the bench are TA-Lib 0.4.28, pandas-ta 0.3.14b, and finta 1.3 — one Python wrapper around a C library, and two NumPy/pandas-backed implementations that push their hot loops down into NumPy’s C internals. There is no widely-used pure-Python TA library in the Python ecosystem I can put ta.py next to the way ta.js sits next to technicalindicators or trading-signals. So the framing — that the right axis to measure ta.py on is pure-Python-against-pure-Python — is a posture, not a benchmarked claim against a named field. What the bench in the repo actually measures ta.py against is the NumPy/C-backed field the framing already concedes it expects to lose to, plus an internal naïve textbook baseline that the sliding-window rewrites are meant to beat. The bench methodology and pinned competitors live at bench/README.md; per-run result tables are intentionally not committed, because absolute numbers do not generalise across machines and the bench’s own README is explicit about that.
I did not start the Python bench from a principled “compare only against pure-Python libraries” stance — I expected ta.py to be competitive against everything in the ecosystem, got the C-bound numbers, and only then walked back to the framing above. If you need maximum speed in Python and you are willing to take a C dependency, the C-bound libraries are still the answer. ta.py is the answer when you cannot or will not.
ta.go followed the same pattern as ta.js — pure Go, compared against the pure-Go alternatives in the ecosystem, no FFI shenanigans. The comparison set was markcheno/go-talib (pinned to a January 2025 build, since there is no semver tag for it) and cinar/indicator 1.3.0. Both are pure-Go — go-talib, despite its name, is a Go port of TA-Lib rather than a CGO wrapper, which is why the bench runs cleanly with CGO_ENABLED=0. The bench lives in a separate go.mod inside the repo so those benchmark deps never leak into anyone’s go.sum when they install ta.go itself; the published table is at bench/BENCHMARKS.md and the reproduction steps are in bench/README.md.
The result was that pure-Go ta.go wins or ties every cross-library case at 100k bars. Against markcheno/go-talib — the pure-Go port of TA-Lib, which should be the harder comparison of the two — ta.go is faster on SMA (1.30×), MACD (1.18×), Bollinger Bands (1.25×), and ATR (1.90×), and within run-to-run noise on EMA and RSI. Against cinar/indicator it wins every indicator outright, with the largest gap on RSI at 3.51× and the smallest on Bollinger at 1.34×. The one outlier in the table is the 10k Bollinger row, where ta.go is slower than both competitors: go-talib skips the rows before the warm-up bar and only emits the post-warm-up series, while ta.go and cinar both emit the full n-l+1-row series. That extra accounting matters more at 10k than at 100k, where the comparison flips and ta.go is fastest on Bollinger as well. The row is in the table honestly rather than airbrushed out — it is the ta.go equivalent of the Rate of Change gap on ta.js, a small constant-factor item I would rather report than hide.
Three libraries, one release
The reason v2.0.0 ships across three repositories at the same version is the same reason the audit and the bench were worth doing in the first place. I have always tried to keep these libraries aligned — what ta.js calls sma should be the same function ta.py calls sma, with the same default parameters and the same output shape. Over the last few years they had drifted, and the drift was the kind that compounds: a fix that landed in one repo did not always land in the others, and the longer that went on, the more expensive bringing them back into sync was going to be.
So I did the alignment work first, before picking up any of the open user issues that had collected on the individual repositories in the meantime. That is not the most user-responsive call I could have made — there are issues sitting in the trackers that did not make it into v2.0.0 — but the alternative was fixing each issue across three drifting libraries and then having to re-align them all afterwards anyway. Doing the v2.0.0 audit and the v2.0.0 bench work first means that from this point forward, fixing one library and re-aligning the family is a smaller piece of work than aligning all three from a v1-era starting point would have been.
A note on what v2.0.0 is not. These are not new libraries. ta.py and ta.go are existing siblings of ta.js that have been part of the family for a while — anyone using one of them has been using the v1-era version of it. v2.0.0 is the version cut that brings them up to a common audited spec, with a common bench methodology, and ships them at the same version number for the first time. It is the first time the three libraries actually agree with each other end-to-end.
Honest caveats
Things I know are imperfect on the v2.0.0 release. Not as a footer; as the part of the post that gives the rest of it any credibility.
No outside cross-validation yet. The bench harness ships in each repository, the hardware is specified, the competitor versions are pinned, and anyone who clones the repos can re-run the comparisons themselves. I am hoping that someone does. As of right now, the only person who has run the v2.0.0 numbers is me, and the post is partly a call for that to change. If you run the bench and your numbers disagree with mine — on different hardware, on a different runtime version, with a different competitor version — open an issue. I would rather find out now than after the numbers have sat there as if everyone agreed with them.
The Python bench is not the same kind of evidence as the ta.js bench. There is no widely-used pure-Python TA library to put ta.py next to the way ta.js has pure-JS peers, so the comparison the bench section draws — pure-Python-against-pure-Python — is a posture about what a fair benchmark would even look like, not 66-of-67 against a named field. If that is what you were reading for, the Python bench does not have it.
The Rate of Change indicator on ta.js is around 22% behind @debut/indicators at 100k bars. I shipped it that way rather than holding v2.0.0 for it because the rest of the cross-library wins were already comprehensive and the gap on roc is a constant-factor one I can close in a later round. “Wins 66 of 67” reads worse than “wins all of them” but I would rather ship 66 of 67 honestly than dramatise the 67 by keeping the release on the shelf. There are a couple of other indicators across the family in similar shape — small enough margins that the next round of perf work should mop them up. I would rather try to beat them all eventually than pretend I already do.
The hand-maintained legacy minified bundle for ta.js — the one that predates the esbuild pipeline — still ships with the package. This is not a drift footgun the way it might look from the outside. It is a deliberate backwards-compatibility commitment to people who are still pulling that file off a CDN in browser apps that have been running for years. Removing it would silently break those apps, and the cost of keeping the file around is one I am happy to pay. The two esbuild-generated bundles are the modern path; the legacy file is the not-breaking-existing-users path.
The audit only happened because the v1 test suite was not actually telling me when an indicator was wrong. It is fair to ask why that took as long as it did to surface, and the honest answer is that the suite stayed green and I trusted it for longer than I should have. Some of the indicators it was certifying as correct had been wrong since the first commit on them. That is a kind of mistake you do not catch by looking at the test runner output, because the runner is already telling you everything is fine. You catch it by reading the indicators against the textbook, and that is a separate pass that did not happen until v2.0.0.
Where it sits now, and what is next
ta.js, ta.py, and ta.go are all live at v2.0.0 and in maintenance mode. I am not planning a wave of new functions on any of them right now. What I am planning, over the coming months, is to work through the open issues that have collected on the individual repositories and that did not make it into v2.0.0. The pattern is going to be sequential: fix the library with the most pressing pile of issues, re-align all three so the fixes do not leave the family drifting again, move to the next library, repeat. That is the maintenance shape that I think actually keeps a multi-language family healthy without spending more time on alignment work than on actual fixes.
The bench harness ships in each repo and is meant to live there as a forcing function, not just as the artifact behind v2.0.0’s claims. Future perf rounds run against it. Future correctness fixes are validated against the same fixtures the audit produced. If the next time someone files an issue is “this indicator gives a different output on this input,” the regeneration-from-textbook fixtures and the cross-library bench let me check the report against several other libraries’ implementations of the same function. That triangulation is what makes the bench worth carrying as part of the project rather than just running it once for the announcement.
If you have been using one of these libraries on its v1-era version, the migration to v2.0.0 is breaking on the formulas the audit fixed. The output of the indicators that had bugs has changed, because the bugs are gone. There is no migration script for that — anyone whose code consumes the v1-era output of those indicators has to look at whether their code was depending on the right answer or the wrong one. The release notes in each repo carry the list. If your usage was on indicators the audit did not flag, v2.0.0 is a drop-in.
What I would actually like out of this announcement is for someone other than me to run the bench. The numbers are reproducible. The hardware is specified. The competitor versions are pinned. If you maintain or use a TA library in any of these three languages and you care about the comparison being fair, the bench is already in the repository and it takes one command to run. Whatever you find — agreeing with me, disagreeing with me, or surfacing something I missed — is the input I most want for v2.0.x. I am not trying to be the only person whose numbers are on the record for this comparison. I am trying to be the first.
Related reading
-
A hundred technical indicator functions in JavaScript
My first opensource project is a technicalanalysis library called — around a hundred indicator functions in JavaScript, first commit on 20200824, v1.17.0 shipped earlier this week. I started it…
-
Two weeks of agentic coding into a paywalled SaaS category
I built Hourly in two weeks with agentic coding to test whether a paywalled SaaS category — WorkingHours, Toggl, Timery — is still defensible.
-
The adoption gap
I changed my mind about agentic coding loops. Most of my work this year was built next to one — and the honest read on what it lifts and what it leaves behind.