A research pipeline for the internet-shaped part of the decision
I built a research pipeline to help me pick a Dutch e-commerce niche to launch into. Version 1 pointed me at one. I launched a webshop on it, made a sale, and shut the shop down for reasons the pipeline had no way to see. Version 2 was built with more rigor and I trusted it less, because by then I had learned which layer of the problem a pipeline like this doesn’t touch.
It is a 5-stage pipeline — crawl, classify, embed, cluster, analyze — that processes around 177,000 Dutch e-commerce domains and produces a ranked list of niches that look like blind spots: high search volume or known category revenue, under-populated online supply. That is what I asked it to find, and on its own terms, it found them. The niches were real and a working store was buildable on top of the output — the pipeline did the job I gave it. What the pipeline had no way to surface was the operational layer underneath the niche, and that is where the honest story of this project lives: the e-commerce and dropshipping work around a niche like this is miserable, the margin relatively small, and once I had launched a real store and seen up close the kind of service I would be providing to a customer, I had no interest in running it regardless of how clean the ranking had been.
The overall shape
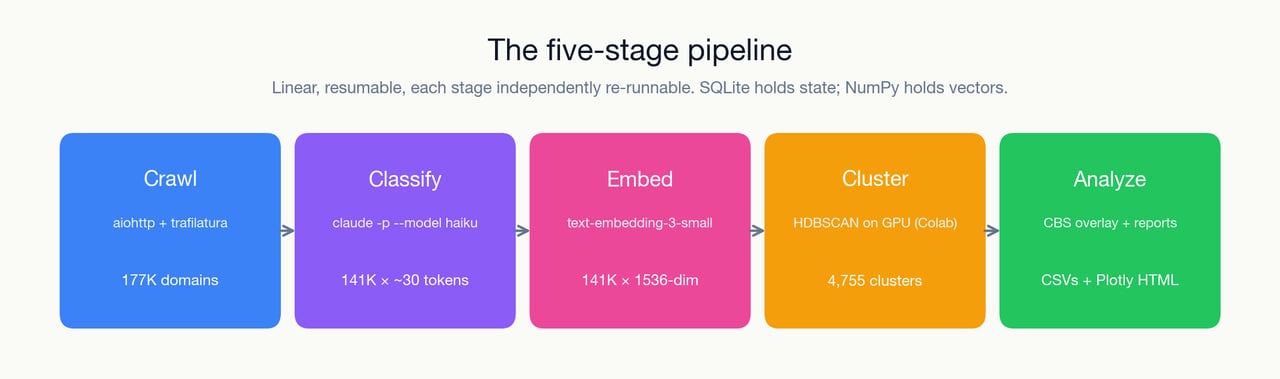
The source is not the open web. It is the output of two earlier projects of mine — one that mapped out the Dutch domain space for research purposes, and one on top of it that filtered the list down to the domains likely to be running an e-commerce store. Roughly 177K of them, sitting in MongoDB by the time this pipeline starts reading. The pipeline doesn’t crawl from scratch — it processes a curated list.
The classifier is Claude Haiku, called once per domain, with async concurrency capped at around ten in-flight calls. The per-call cost at that shape was low enough that rerunning the whole corpus across pipeline versions never became a budget conversation.
The embeddings are OpenAI’s text-embedding-3-small, 1536-dimensional, applied to the classification text (industry + niche + products + keywords + USPs) rather than the raw HTML of each crawl. The embedding dataset ended up around 141K × 1536 at float32.
Clustering is HDBSCAN on a 20-dimensional PCA projection. I started with it running locally on CPU, and at the full corpus size the run was slow enough to be unusable — the CPU would thrash for hours and still not hand me a clustering I could iterate on in a single sitting. So the run that actually matters now happens on Google Colab via cuML RAPIDS GPU. Local CPU clustering code still exists in the codebase, but I never actually run it at full corpus size — it only gets touched for small test subsets. The real path is an .npz round-trip through a Colab notebook, which means the pipeline is not actually a single end-to-end command — the clustering step happens off-machine, and the rest of the pipeline has to hand off to it and pick the result back up.
Finally, cluster-level opportunity scoring. Cluster keywords are matched against Dutch SBI industry codes, then joined to the CBS (Centraal Bureau voor de Statistiek) OData API for a per-sector revenue index and year-on-year growth. The output is a CSV of ranked “dropshipping opportunities,” sorted by a gap score. A number, authoritative-looking, and I will come back to what it is and isn’t worth — not least because I did not actually use the SBI/CBS half of it to pick a niche. In practice I treated the clustering output as idea generation and left the pipeline there. I took each candidate niche by hand and checked advertiser activity on Meta and Google; whether anything serious was running on either platform was what told me a niche had real weight behind it, on top of the obvious filter of whether it was something I actually wanted to build.
Where V1 sent me, and what happened
V1 of the pipeline was a smaller setup — local MiniLM embeddings on raw page content, CPU clustering at a smaller scale, no CBS overlay. It produced a ranked shortlist, I picked a niche off that list, and I built a real webshop around it. The shop made a single sale and I shut it down within a month.
The reason it died was in operations, not in niche selection. It was a dropshipping business on personalized items manufactured in China, which meant shipping times long enough that my first and only customer was complaining about delivery before anything else had a chance to go wrong. The shape of the next few months was clear from there: most of my time would go into shipping-support emails, and almost none of it into actually developing the store. I am writing that project up separately as its own post-mortem; for the purposes of this post the story is just: the pipeline’s output was actionable, and I acted on it. The pipeline did not point me at the wrong niche. It pointed me at a niche where the thing that was going to kill me — the operational layer below the website itself — was not something a pipeline of this shape could measure. That ended up being a more useful piece of learning than anything the CSV was going to hand me. Running a real store for long enough to see where my days would actually go made it click that I did not want to be in e-commerce — not the market, but the day-to-day of operating a store. Whatever margin a good niche could throw off, the work that came with running the thing was going to make me unhappy, and roughly a month of actually doing it was the cheapest honest way to find that out.
That is the load-bearing move the rest of this post sits on. The pipeline was not silent because of a bug. It was silent because the thing it was looking at — what’s on the internet, in aggregate, in Dutch — is a different object from the thing that decides whether a specific operator can run a specific store profitably. Fulfillment, unit economics, the day-to-day of running a particular category — none of that shows up in an embedding of a crawled homepage.
Why V2 was more rigorous, and I trusted it less
V2 was, technically, better on every dimension I built it to be. More domains in the corpus. OpenAI embeddings on classification text instead of local MiniLM on raw HTML, which cut through a lot of footer-boilerplate noise and produced clusters I could actually read. HDBSCAN on cuML GPU instead of a CPU thrashing for hours. A CBS overlay that scored each cluster against public revenue and growth data — although I am still genuinely unsure whether this last one actually improved the output or just made it look more authoritative. By every metric I had set for the rewrite, V2 was the version the pipeline was supposed to be.
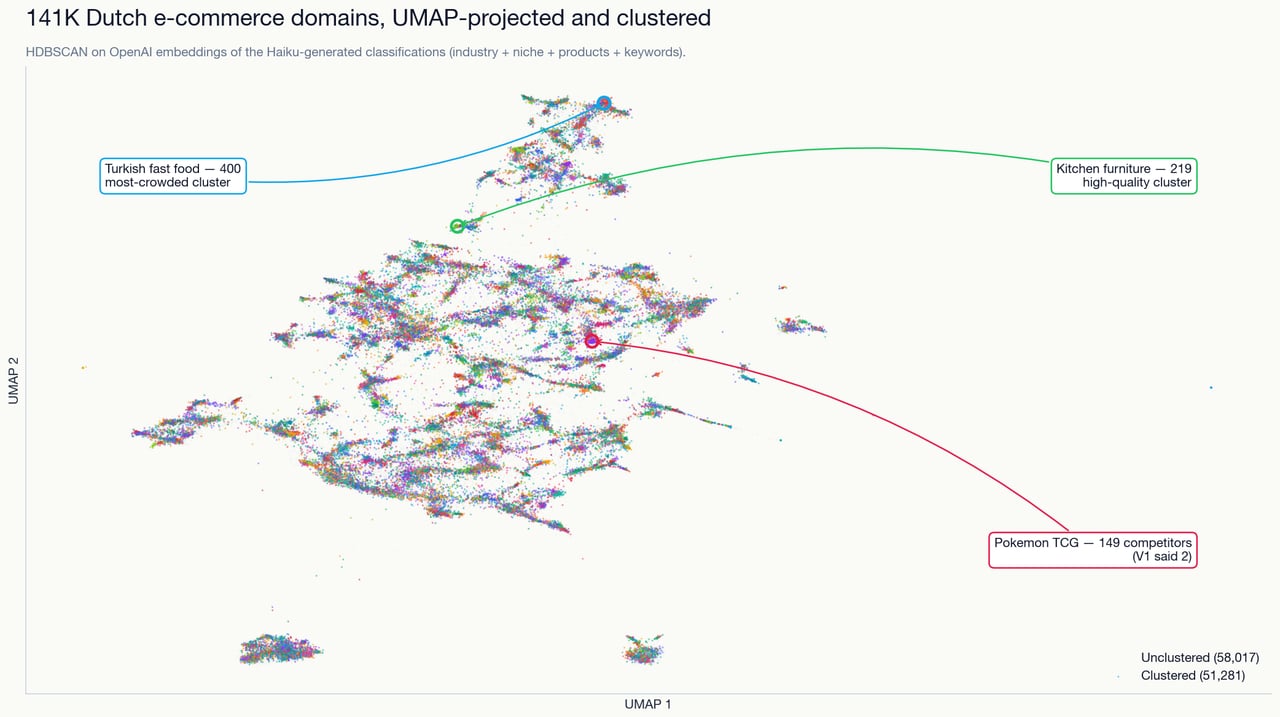
And the headline finding of V2 was that V1 had been confidently wrong in several places. The clearest example is Pokemon TCG. V1 had come back with 2 competitors in the cluster — a gap, a wide-open niche, go now. V2 came back with 149, including effectively every established card shop in the country. Same market, same pipeline shape, different embedding and different scale, wildly different competitor count.
That correction should have been the moment the pipeline earned more of my trust, not less. V2 was the instrument correcting itself, which is the behaviour you want out of a research tool. The problem was that I was already skeptical before V2 told me. A friend of mine is actually in the Dutch TCG market, and he had already told me — in the most low-tech way possible, a conversation — that the market was a lot bigger than V1’s output suggested. So when V2 came back with 149, it was not a revelation. It was the pipeline catching up to a conversation I had already had, weeks earlier, with a single person who knew the category.
That is not a flattering data point for 141K × 1536-dimensional embeddings. One conversation with one friend produced a more accurate read of Pokemon TCG competition than V1 did, and V2’s agreement with the friend only ratified a picture I already had. The pipeline’s role in that particular niche was retrospective: it eventually got the right answer, long after I had gotten the right answer somewhere cheaper.
I do not want to generalise hard from a single data point. But I never found a niche in V2’s output that I had independent ground truth on and where the pipeline was ahead of the ground truth. By the time I had any real belief about a niche, it had come from somewhere else — a friend, a forum, a market I already lived adjacent to — and the pipeline was either agreeing with that or contradicting it against a picture that was more legible to me than the pipeline’s. The honest caveat on the whole project, the one the codebase will not tell you, is that I did not set up a deliberate protocol for validating a candidate niche against a human in the market. I had one accidental data point, and it landed late enough to set the tone for the rest of the runs rather than early enough to redirect the design of the pipeline itself.
Things I would cut on a rewrite
There are a few specific things in the repo I would delete if I came back to it with fresh eyes.
Three parallel embedding pipelines — OpenAI on classification text, local MiniLM on raw HTML, and a third running on domain names only — ended up coexisting, each introduced to patch a different problem with the one before it. Only the OpenAI path is actually load-bearing for the rest of the pipeline. The domain-name pipeline produced its own retro document admitting that tokenising Dutch second-level domains with a Dutch-language BERT made the clusters worse rather than better (the top cluster keywords it produced were things like “dam”, “ster”, “min”, “mijn”, “van” — i.e. substrings of domain names, not topics). On a rewrite I would pick one embedding path and delete the other two.
The CBS SBI keyword-match scoring — the last stage of the pipeline, the one that takes a cluster’s top keywords, tries to map them to a Dutch SBI industry code, and then joins that code against CBS revenue and growth data to produce the final opportunity ranking — is doing less work than it looks. That keyword-to-SBI match is itself a keyword-overlap heuristic, and that heuristic is imprecise enough to map dental clinics to hotels if you let it. There is a match_score >= 3 filter in place to cut the worst cases, but no evaluation of how often it drops good matches on the floor. The opportunity score itself is a weighted combination of five subscores — competition, quality, e-commerce ratio, physical-goods ratio, dropship-friendliness — with weights of 0.25 / 0.20 / 0.20 / 0.15 / 0.20. The gap score between cluster demand and cluster supply is (revenue_index * growth_factor) / sqrt(cluster_size). Both formulas look authoritative. The weights in the first one are not justified anywhere in the repo. They are vibes. The second one is a plausible-looking gut feeling with a square-root in it. None of which ended up mattering much in practice, because I stopped leaning on this stage to make a call once it became clear how inaccurate it was — the dental-clinics-to-hotels mismatch is the kind of thing that kept showing up, and from that point on I treated its output as background noise rather than signal and made the actual picks from the clustering output plus the manual ad-activity check described earlier.
The hybrid embedding I already knew I should be using never made it in. A 0.5 * raw_page + 0.5 * classification blend would have been the obvious fix for the “classification-text-only is hostage to the classifier” problem — I had a note to myself saying exactly that, and then never went back to implement it. Between approaches I had already decided were better and approaches I had actually shipped, the ratio of the former to the latter in this codebase is higher than I am comfortable with.
There are also zero tests. The pipeline’s correctness was validated by reading the output CSVs and going “yeah, that looks right.” That is exactly the way V1 had convinced me of things V2 later retracted — it produced outputs that looked right, and I did not have anything other than my own pattern-matching standing between the output and me believing it.
What I would carry into the next thing
Honestly, not that much that generalises. Haiku was the right model for this kind of structured-extraction-over-a-large-corpus job — cheap per call, accurate enough on the classification schema to give the downstream clustering something clean to work on, and forgiving of the fact that each input was a messy crawled homepage rather than a neatly prepared prompt. If I run into another large-batch classification problem in the near future, Haiku is where I would start, and I would also want to test a tier below it to see where the accuracy cliff actually sits — for this shape of job it is plausible that something cheaper than Haiku is already good enough, and I never ran that experiment. The direction I did try, and that did not work, was the other way: I spun up a Runpod instance running DeepSeek R1 against the same classification prompt, and it was worse on every axis I cared about — slower per call, noticeably more expensive to run, and the extra reasoning tokens were not buying me any accuracy on a task that is effectively structured extraction from a crawled homepage. For this shape of problem the ceiling is not set by how smart the model is. It is set by how clean the input is and how well the output schema is constrained. Beyond that, the rest of the pipeline is too wedded to this niche-hunt in this market to carry cleanly into anything else.
Where it sits now
The project is parked. The last real run is from mid-March, and there have been no meaningful commits since. It is not dead — I have not deleted the repo, and there is no specific decision to kill it — but it is not actively developed either, and I do not have an immediate plan to reopen it.
If I did reopen it, the only honest path is to ship it as a Dutch market-intelligence SaaS for other operators — something that takes the clustering output, the classifier pipeline, and a cleaned-up version of the CBS overlay, and wraps them in a UI somebody other than me can pay for. The framing would be idea-generation rather than a ranked opportunity list: here are legible clusters of the Dutch market, here is rough revenue and growth context at the sector level, now do your own validation — because a niche has to fit the specific operator for any of it to work, and CBS data is broad enough that a high-earning sector can still be hiding high startup costs or an operational mess the numbers will not show. The keyword-to-SBI mapping as it currently stands would not be what ships; the idea behind it is sound, the way I implemented it is not. I have not gone down that road because it does not have a customer yet, and the only customer the CSVs currently have is me, and I am not buying.
If you are building something adjacent — a market-intelligence pipeline, a large-batch LLM classification job over a messy corpus, or a retrospective on a research tool that ended up producing better questions than answers — I would be interested in comparing notes.
Related reading
-
An agent built around not calling the LLM
A personal agent built so the default question every tick is whether the model needs to be called, and an architecture where the answer is usually no.
-
A diamond painting shop the code could not save
I built a custom Node webshop for personalized diamond paintings, sold one canvas, and shut it down inside a month. The supplier was the bottleneck.
-
Introduction
I'm Nino Kroesen, operator-developer in the Achterhoek. The site covers production systems, slow-feedback research, and shipped independent experiments.